While working with data teams, we keep running into the same quiet problem: data that almost matches, but not quite. A name entered slightly differently, a missing identifier, or a small formatting change is individually minor, but together they create a fragmented view of what should be a single record.
A large U.S. healthcare study highlighted this clearly, uncovering nearly 400,000 duplicate patient records. Most weren’t caused by system failures but by everyday inconsistencies, mismatched IDs and simple name errors. The kind of issues exact matching was never designed to catch.

That’s the gap fuzzy matching fills. It doesn’t look for perfection—it looks for similarity. It connects records that appear different but represent the same entity, helping turn scattered data into something reliable.
In this blog, we’ll explore how fuzzy matching works, why it matters, and how it helps you make smarter decisions with imperfect data.
What Is Fuzzy Matching?
Fuzzy matching is a data matching technique used to identify records that are similar but not identical.
In simple terms, it helps your system recognize that two pieces of data might actually refer to the same person, company, or record, even if they’re spelled differently or formatted inconsistently. It is widely used in CRM systems, data deduplication, and lead-to-account matching to unify inconsistent data.
For example:
- “Jon Smith” and “John Smith”
- “Acme Ltd.” and “Acme Limited”
- “leadangel.com” and “Lead Angel Inc.”
Now that you know what fuzzy name matching is, let’s look at some common fuzzy matching algorithms and their use cases.
Common Fuzzy Matching Algorithms, Use Cases and Tools
Fuzzy matching systems rely on one or more of these algorithms, each optimized for different types of similarity:
| Algorithm | What It Does | Best For |
|---|---|---|
| Levenshtein Distance (Edit Distance) | Counts how many insertions, deletions, or substitutions are needed to transform one string into another. | Detecting typos or small spelling errors |
| Jaro-Winkler | Focuses on matching the beginning of strings and character transpositions. | Matching person names or short text |
| Soundex / Metaphone / Double Metaphone | Converts words into phonetic codes to compare how they sound. | Handling names with similar pronunciations (“Smith” vs “Smyth”) |
| Token-Based Matching (e.g., Token Sort / Token Set Ratio) | Breaks text into tokens (words) and compares them irrespective of order. | Company or organization names (“Acme Corp” vs “The Acme Corporation”) |
| N-Gram Similarity | Splits words into short overlapping sequences and compares shared patterns. | Detecting partial or fragmented matches |
| Cosine Similarity / TF-IDF | Uses vector space modeling to compare longer text fields. | Matching descriptions or unstructured text |
| Jaccard Similarity | Measures the overlap between two sets of characters or words. | Matching tags or unordered lists |
| Hybrid / Weighted Models | Combine multiple algorithms for higher precision. | Enterprise-level systems |
Top Use Cases for Fuzzy Matching Algorithm
Fuzzy matching isn’t just a behind-the-scenes data cleanup tool; it’s a key driver of CRM accuracy, lead management efficiency, and data-driven decision-making.
Here are some of the most impactful ways organizations use fuzzy matching algorithms today:
1. CRM Deduplication
Duplicates creep into CRMs through forms, imports, and manual entries. Fuzzy matching identifies records that appear different but represent the same entity; for instance:
- “Brightwave Technologies” vs. “Bright Wave Tech”
- “Apple Inc.” vs. “Aple Incorporation”
- “Soda Co.” vs. “Soda Company”
The system calculates similarity scores and flags potential duplicates, allowing you to merge or verify them confidently.
Result:
Cleaner records, fewer reporting errors, and a more reliable customer database.
2. Lead-to-Account Matching
Not every incoming lead looks identical to your existing account data. A new lead might register as “samuel@softmonk.io,” while your CRM lists “Soft Monk Solutions.”
Fuzzy matching algorithms for company names, email domain, and phone numbers to connect the dots automatically.
Example:
“Greenfield Agri Systems” and “Green Field Systems Pvt Ltd” would be identified as the same organization.
Result:
Smarter lead routing and seamless sales handoffs; no lost opportunities.
3. Record Linking Across Systems
Data rarely lives in one place; companies often maintain multiple systems like Salesforce, HubSpot, or SAP.
Fuzzy matching acts as the “translator” that links records across platforms, even when formatting, abbreviations, or naming conventions differ.
Examples:
- “Mole Analytics” (in Salesforce) ↔ “Mole Data Labs” (in HubSpot)
- “S. O’Brien” (in ERP) ↔ “Sean Obrien” (in CRM)
Result:
A single, 360° view of every customer and account, without manual data reconciliation.
4. Data Quality & Enrichment
Data decays fast; typos, outdated records, and inconsistent naming can quietly undermine your CRM.
Fuzzy matching algorithm continuously scans your datasets to spot anomalies, variations, or partial matches.
Examples:
- “Salmon Retail Pvt. Ltd” vs. “Salmoon Retail Private Limited”
- “North Ridge Health” vs. “Northridge Healthcare”
By automatically identifying these near-matches, fuzzy matching logic helps maintain high-quality, standardized, and enrichment-ready data.
Result:
Consistent, trustworthy data that powers more accurate segmentation, analytics, and automation.
Fuzzy Matching Tools (Description, Key Features & Pricing)
WinPure
WinPure is a no-code data quality platform designed to clean, match, and deduplicate large datasets using fuzzy matching and AI-powered entity resolution. It’s built for both technical and non-technical users.
Key Features:
- AI-powered fuzzy matching & entity resolution
- Data cleansing, profiling, and standardization
- Merge, purge, and deduplication workflows
- Address verification and data enrichment
- Automation and batch processing
Pricing:
- Starts around $599 (one-time license) for basic versions
- Advanced plans are custom-priced based on data volume and usage
LeadAngel
LeadAngel is a lead routing and fuzzy data matching platform focused on B2B teams. It uses fuzzy matching names to improve lead-to-account matching, deduplication, and CRM data accuracy.
Key Features:
- Lead-to-account matching
- Advanced lead routing automation
- Data deduplication and enrichment
- CRM integrations (Salesforce, HubSpot)
- Territory and account-based routing
Pricing:
- Pricing is custom (quote-based) depending on features and scale
OpenRefine
OpenRefine is an open-source data cleaning tool that allows users to explore, clean, and transform messy datasets. It includes clustering features for fuzzy matching.
Key Features:
- Clustering-based fuzzy matching
- Data transformation and normalization
- Faceted filtering and bulk edits
- Local processing (data stays on your machine)
- Highly customizable (open-source)
Pricing:
- 100% Free (open-source)
Talend Data Quality
Talend Data Quality is an enterprise-grade platform that integrates data profiling, cleansing, and fuzzy matching into broader data pipelines.
Key Features:
- Data profiling and cleansing
- Fuzzy matching and deduplication
- Data governance and compliance
- Cloud and hybrid integrations
- No-code / low-code pipelines
Pricing:
- Around $10,000–$12,000/year per user license
- Can go up to $20,000/year for enterprise licenses
- Also offers custom/usage-based pricing tiers
IBM InfoSphere QualityStage
IBM InfoSphere QualityStage is a high-end data quality and entity resolution tool used for complex matching, deduplication, and large-scale data integration.
Key Features:
- Advanced probabilistic matching
- Entity resolution across multiple systems
- Data standardization and cleansing
- Scalable enterprise architecture
- Integration with IBM data ecosystem
Pricing:
- Custom enterprise pricing (not publicly disclosed)
- Typically high-cost, enterprise-level investment
How the Fuzzy Matching Algorithm Works
When a system performs a fuzzy matching algorithm, it doesn’t simply check if two entries are the same; it analyzes them at multiple levels to measure how similar they are. This process typically includes:
Data Preprocessing (Normalization)
Before any comparison happens, the data is cleaned and standardized, removing spaces, converting text to lowercase, and handling symbols like “Inc.” or “Ltd.” This ensures consistent inputs for comparison.
Similarity Scoring
The system then compares the cleaned values using one or more algorithms that calculate how “close” the two strings are. Each fuzzy name matching algorithm works differently; some focus on spelling, others on sound or word order.
Threshold Evaluation
Once scores are calculated (usually between 0 and 100), the system applies a matching threshold. For example, anything above 90% might be considered a “strong match,” while 70–89% could be flagged for review.
Decision & Action
Based on the similarity score and business rules, the system can automatically link, merge, or flag the records for human validation.
How LeadAngel Handles Fuzzy Matching to Make Your Data Work Smarter
Ever wonder how your CRM always seems to know that two slightly different records belong to the same lead? That’s not luck; it’s smart fuzzy name matching at work.
Here’s how LeadAngel makes that happen, step by step, turning messy, inconsistent data into clear, connected insights your team can actually trust.
1. Ingest & Normalize
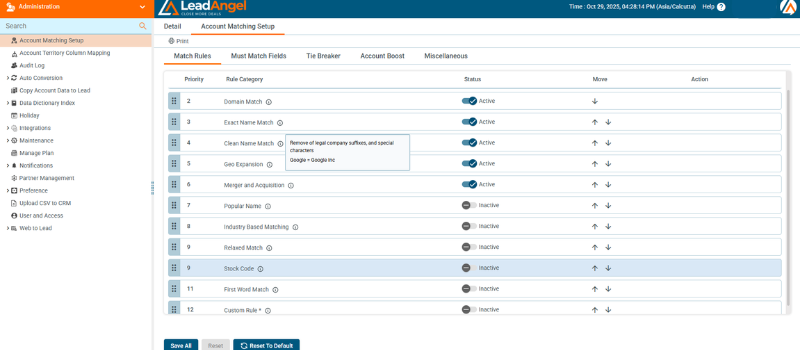
Standardizes records (names, emails, phone formats, suffixes, special characters, and spacing) to prepare for accurate comparison.
2. Multi-field Comparison
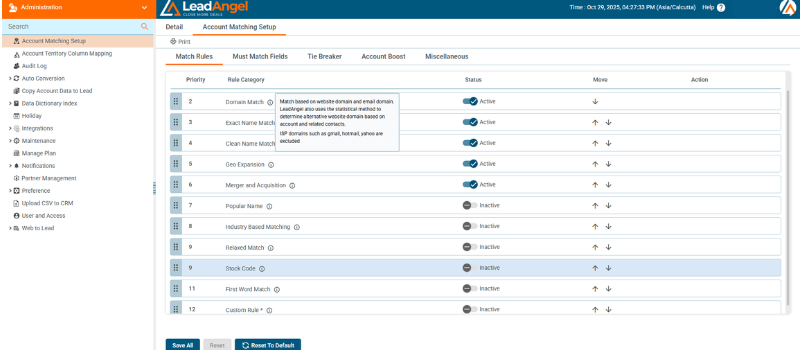
The engine compares multiple attributes like company name, email domain, and phone number to find intelligent matches.
3. Algorithm Ensemble
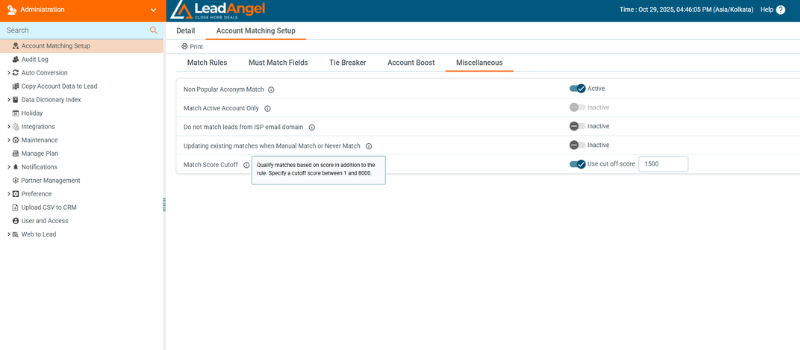
Multiple algorithms (edit-distance, phonetic, token, and domain-based) run simultaneously, and their results are weighted into one similarity score.
4. Confidence Scoring & Routing Rules
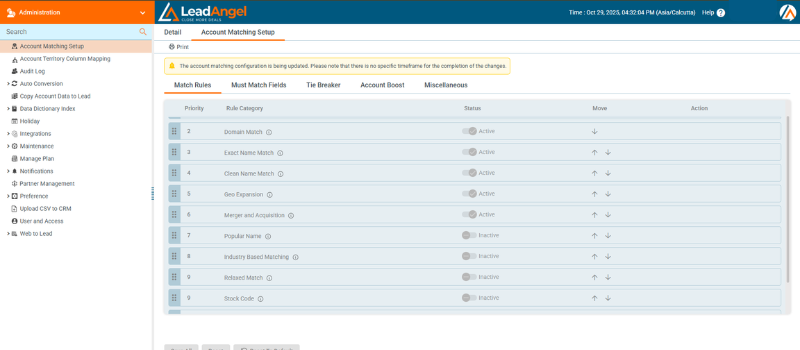
Each match is scored by confidence level. Once a match meets defined criteria, LeadAngel temporarily freezes the record to prevent duplicate routing or merging. The record remains locked until the lead router completes processing, after which it unfreezes automatically to allow updates or new actions.
5. Continuous Learning
User feedback and routing outcomes refine thresholds, improving match precision over time.
Conclusion: Where Similarity Becomes Certainty
In real-world data, nothing matches perfectly, and that’s exactly where fuzzy matching proves its value. What looks like noisy misspellings, variations, or incomplete records is often just hidden signal waiting to be connected. The ability to recognize “almost the same” as “the same” is what transforms fragmented data into meaningful relationships.
With LeadAngel, fuzzy matching doesn’t stop at similarity; it operationalizes it. By layering normalization, multi-field intelligence, and weighted scoring, it turns partial matches into confident decisions that drive accurate routing and unified records.
Because in modern data systems, precision isn’t about exact matches; it’s about knowing when different inputs point to the same truth.
See How LeadAngel Can Transform Your Lead Management
Curious to experience the power of LeadAngel firsthand? We understand!
We're offering a complimentary trial so you can explore LeadAngel's features at your own pace. Once you request a free trial, we'll schedule a personalized onboarding session to ensure you maximize the value of LeadAngel.
Ready to take your lead management strategy to the next level? Request your LeadAngel trial today!
In addition to exploring the platform, we recommend visiting our LeadAngel Help Center for in-depth guidance. Our dedicated customer support team is also available to answer any questions you may have at sales@leadangel.com.
FAQs
Exact matching looks for identical values. Even small differences break the match. Fuzzy matching finds similarities between records. It uses the best fuzzy matching algorithm to detect variations in spelling, formatting, or wording. This helps match data that isn’t perfectly clean.
Fuzzy matching can be implemented using a fuzzy name matching algorithm like Levenshtein distance or phonetic matching. You can build it in-house or use a fuzzy name matching tool. Many teams also use fuzzy name matching online tools or CRM integrations to automate the process without heavy development.
Data is rarely clean. Names, companies, and emails often have variations. Fuzzy matching helps identify and merge similar records. Using the best fuzzy matching algorithm improves data accuracy, reporting, and decision-making. It also reduces duplicates and manual work.
Building your own fuzzy name matching algorithm takes time and expertise. It also needs constant tuning. A fuzzy name matching tool is better when you want faster setup and reliable results. Most businesses choose ready-to-use or fuzzy name matching online solutions to save time and resources.
LeadAngel uses advanced fuzzy name matching algorithms to identify similar records across systems. It combines rule-based logic with intelligent matching. This helps ensure accurate lead routing and account matching, even with messy data.
Fuzzy matching scans your CRM for similar records. It detects duplicates even when names or fields are slightly different. A fuzzy name matching tool can merge or flag these records. This keeps your CRM clean and improves data quality over time.
Fuzzy matching connects leads to the right accounts, even when data doesn’t match exactly. It uses a fuzzy name matching algorithm to compare company names, domains, and other fields. This improves lead-to-account matching accuracy and ensures leads are routed correctly.
Yes, that’s one of its key strengths. The best fuzzy matching algorithm can recognize variations like “Inc.”, “Ltd”, or abbreviations. A fuzzy name matching tool can also handle spelling differences and formatting issues. This makes it ideal for real-world business data.






